Mar 3, 2025
#architecture
#coding
#ai

In recent years, AI-driven architectural layout generation has made significant progress. However, most of these systems rely on existing datasets that are regionally biased, labor-intensive to produce, and difficult to adapt to different architectural contexts.
This project explores an alternative approach: generating architectural datasets synthetically, using a rule-based algorithm that embeds local regulations, spatial logic, and cultural norms directly into the data itself.
Rather than starting from drawings, the process starts from rules.
Why synthetic data?
1. Existing datasets don’t reflect local architectural culture
Widely used architectural datasets are typically collected from specific regions (Asia, Japan, Finland, etc.). As a result, they encode implicit cultural assumptions about:
room sizes
spatial adjacencies
presence or absence of balconies
circulation logic
notions of privacy and degrees of separation between spaces
When applied to the Turkish context, many of these datasets fail to align with local housing norms and building regulations. This mismatch makes them unreliable for training models intended to operate within local applications.
Synthetic generation allows these cultural and regulatory constraints to be explicitly defined, instead of indirectly learned.
2. Drawing collection is a structural bottleneck
Collecting real architectural drawings is not just slow, it’s structurally problematic:
drawings must be gathered manually
plans need screening, cleaning, masking, and labeling
the process is error-prone and subjective
ethical and copyright concerns are unavoidable
In many AI workflows, dataset preparation becomes the most expensive and fragile part of the pipeline.
This project deliberately avoids drawing collection altogether.
All layouts are generated algorithmically, eliminating both manual labor and ethical ambiguity.
What the generator does
At the core of the project is a rule-based layout generator designed as a case study for one-bedroom apartments.
The algorithm:
operates within local building codes and regulations
randomly generates room sizes, positions, and adjacencies
ensures all outputs remain within valid architectural bounds
produces layouts that are spatially coherent and regulation-aware
Randomness is not used to break rules, it is used inside the rules.
This makes the system flexible while remaining architecturally grounded.

Why this matters
1. Regulations are embedded at the source
Instead of filtering invalid outputs after generation, invalid layouts are never produced.
Room dimensions, adjacencies, and placements are constrained by predefined regulatory limits. This makes the dataset inherently consistent and usable for downstream AI tasks.
2. Scale becomes trivial
Once the rules are defined and validated:
thousands of layouts can be generated with a single run
dataset size is no longer a limiting factor
iteration becomes cheap and fast
For training AI models, dataset size matters and synthetic generation removes that bottleneck entirely.

3. One script, multiple data formats
Because the layouts are generated programmatically, the same dataset can be exported into multiple representations with almost no additional effort:
Textual data
room IDs
room types
widths, heights, areas
→ suitable for language models or symbolic reasoning
Image data
numerical data drawn as floor layouts
→ suitable for CNNs or image-based models
Vector drawings
clean, resolution-independent representations
Graph / node-edge data
rooms as nodes
adjacencies as edges
→ suitable for graph neural networks
This flexibility is one of the key advantages of synthetic data:
the dataset can evolve without manual rework.
Scope and limitations
This study was intentionally framed as a case study:
only one-bedroom apartments were included
the focus was on validating the methodology, not completeness
However, the system is not tied to this typology.
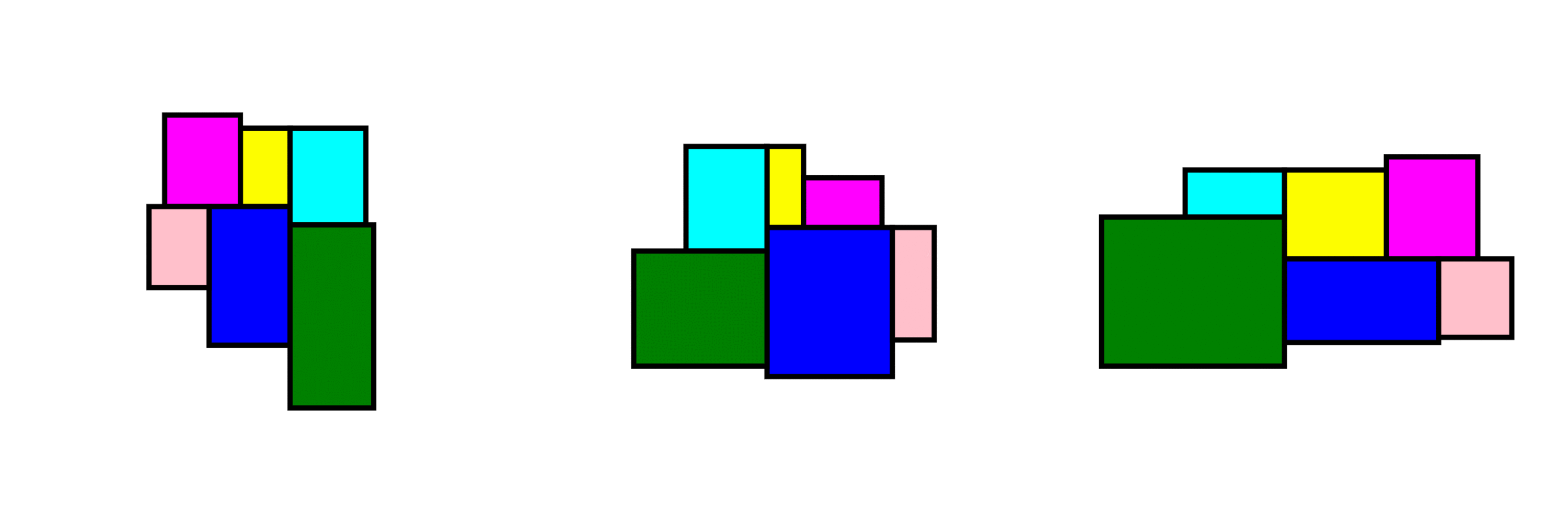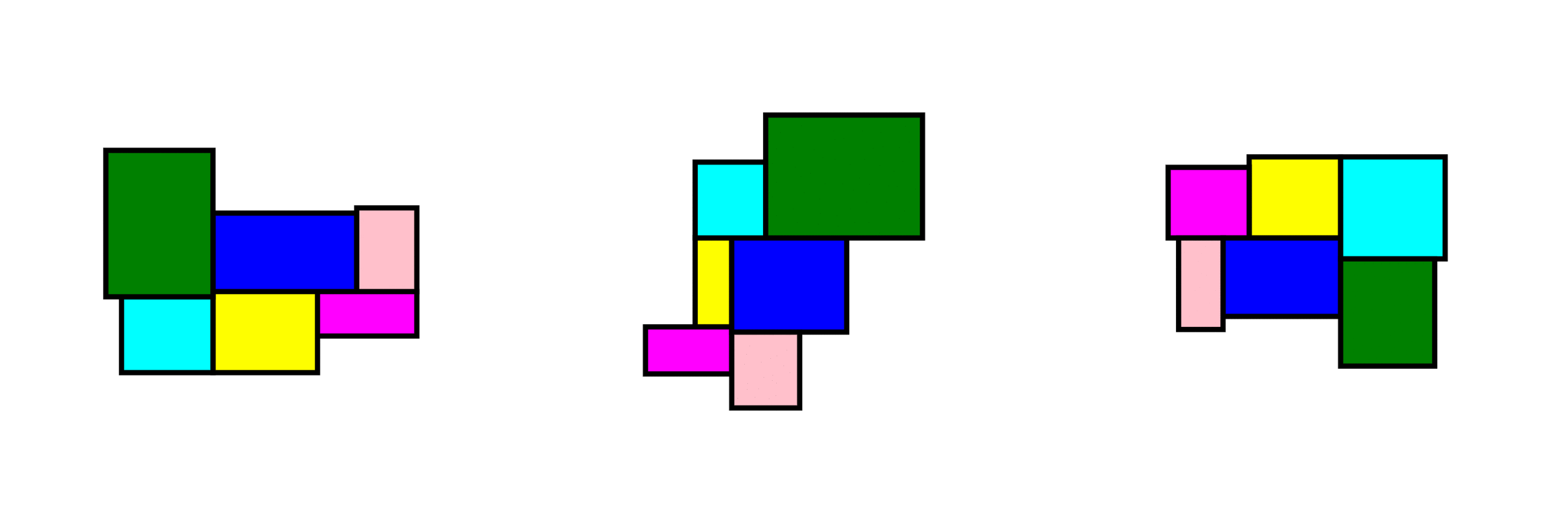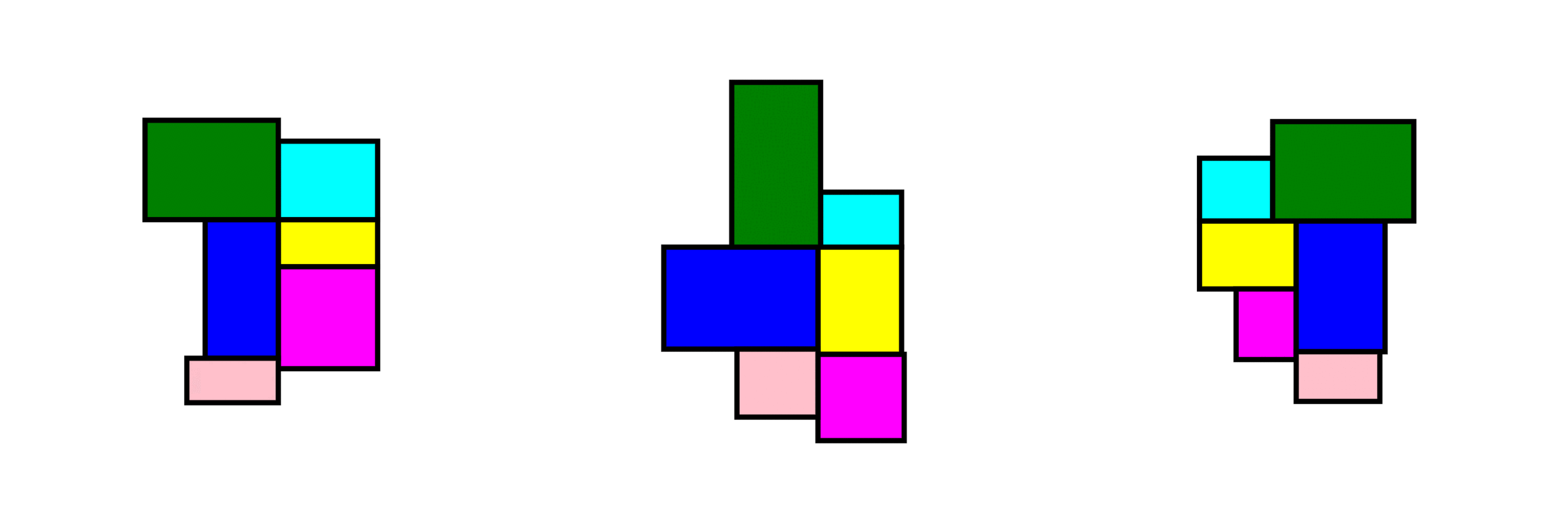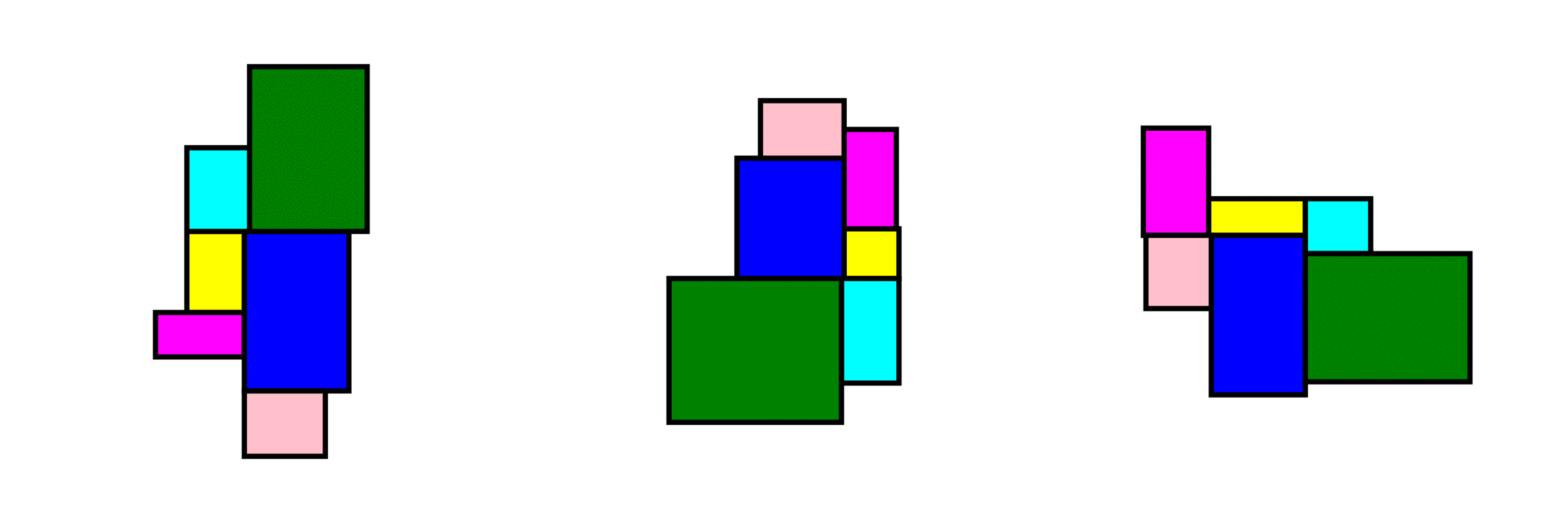
How it can be extended
The same approach can be adapted to:
larger residential units
multi-unit floor layouts
different housing standards
entirely different architectural typologies
By redefining the rules, the generator can be repurposed without changing its core logic.
Closing note
This project treats synthetic data not as a shortcut, but as a design problem.
By encoding architectural knowledge, regulations, and cultural logic directly into the data generation process, it proposes a more controllable, scalable, and adaptable foundation for AI-driven architectural systems.
Project Repository & Live Interface
The Synthetic Layout Generator is available as an open-source project, along with an interactive web interface.
GitHub Repository (source code):
https://github.com/sadikaksu/synthetic-layout-uiLive Web UI (interactive demo):
https://sadikaksu.github.io/synthetic-layout-ui/
The repository includes the rule-based generation logic, layout configuration structure, and deployment setup. The live interface allows real-time exploration of generated one-bedroom flat layouts directly in the browser.